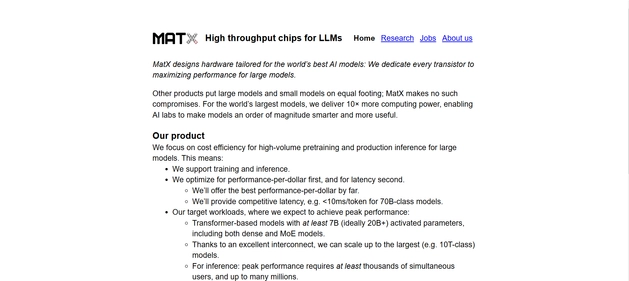
MatX specializes in designing hardware optimized for large-scale AI models, dedicating every transistor to maximize performance for substantial workloads. Unlike general-purpose solutions, MatX focuses exclusively on enhancing the efficiency of large language models (LLMs), providing a significant boost in computing power.
This approach enables AI laboratories to develop models that are exponentially smarter and more functional.
The company’s products are engineered for cost-effective high-volume pretraining and production inference of extensive models. By supporting both training and inference, MatX prioritizes performance-per-dollar, ensuring competitive latency, such as achieving less than 10 milliseconds per token for models with 70 billion parameters.
Their hardware is tailored for transformer-based models with a minimum of 7 billion activated parameters and is capable of scaling up to models with trillions of parameters, accommodating the most demanding AI applications.